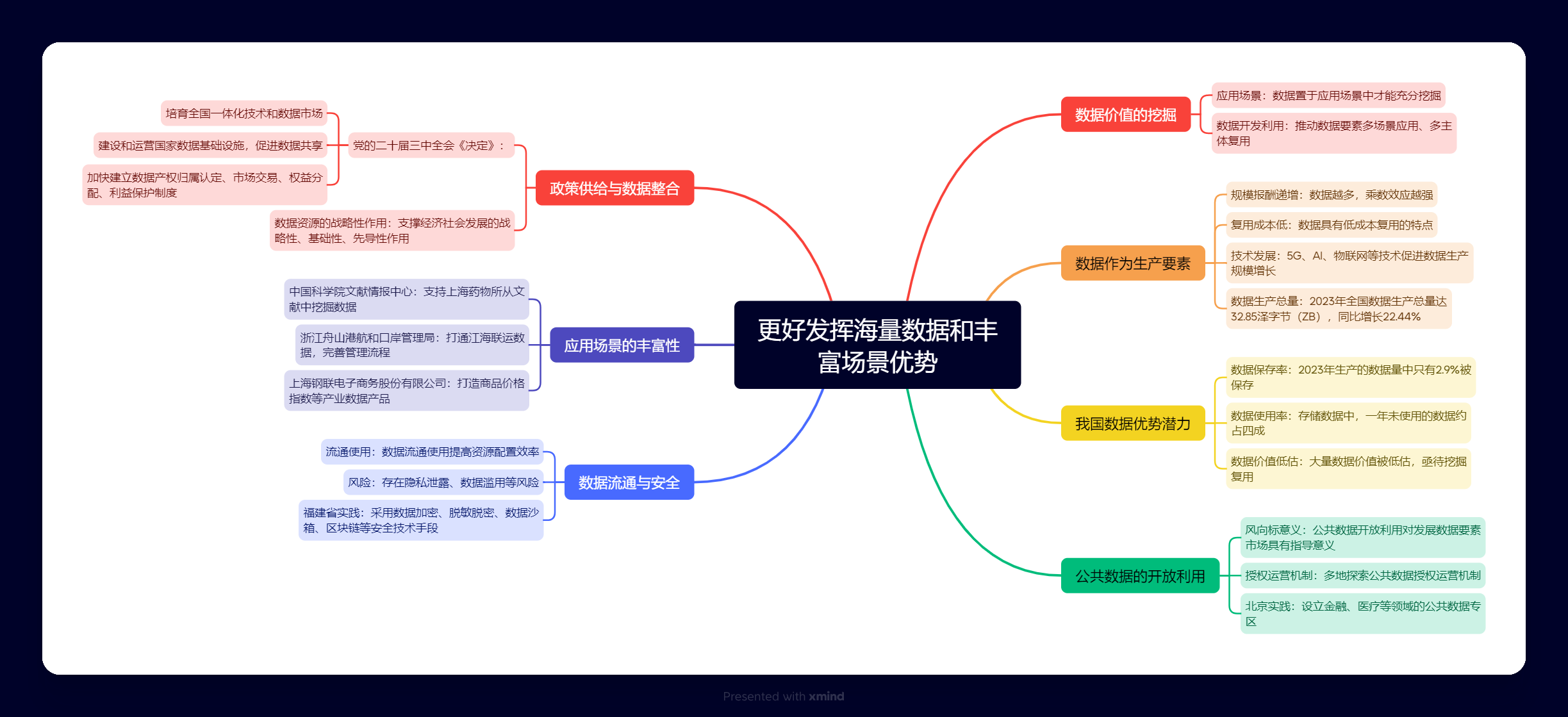
数据价值,只有置于应用场景中才能被充分挖掘。加快数据开发利用,必须推动数据要素多场景应用、多主体复用,创造多样化的价值增量
“在途车辆增加25%,但通行效率却提升一倍。”笔者在2024中国国际大数据产业博览会采访时了解到,一家企业从互联网数据中提炼出对交通管理有价值的道路数据,不依赖硬件感知设备,就能分析每个路口的流量特征,帮助车辆在最优时间通过路口。以数据开发利用辅助城市治理、赋能美好生活,充满想象空间。
数据作为重要生产要素,具有规模报酬递增、复用成本低的特点。有价值的数据越多,数据多源融合形成的乘数效应就越强。得益于5G、AI、物联网等技术的创新发展以及智能设备的规模应用,我国数据生产规模快速增长。2023年全国数据生产总量达32.85泽字节(ZB),同比增长22.44%。
当前,我国海量数据和丰富场景优势潜力亟待释放。《全国数据资源调查报告(2023年)》显示,2023年生产的数据量中只有2.9%被保存,在存储数据中,一年未使用的数据约占四成,大量数据价值被低估,亟待挖掘复用。加快数据开发利用,推动海量数据转化为经济增长新动能、国家竞争新优势,对加快发展新质生产力、推动高质量发展具有重要而深远的意义。
公共数据量大质优,是一片机遇广布的蓝海,其开放利用对发展数据要素市场具有风向标意义。近段时间,多地积极探索公共数据授权运营机制,通过分领域分场景授权、整体统一授权等多种方式,在公共数据开发开放方面取得了一定成效。比如,北京以场景为牵引,设立金融、医疗等领域的公共数据专区,选择具有竞争力的经营主体开展运营管理,创新赋能行业。目前,公共数据资源管理和运营机制改革正不断推进,数据供给动力和市场创新活力得到进一步释放。
合规高效流通、保障数据安全,是推动数据开发利用的重要前提。数据流通使用,有利于提高资源配置效率,也存在隐私泄露、数据滥用等风险,兼具正、负两方面外部性。正因此,要不断优化数据流通环境,聚焦解决普遍存在的“不愿流通”“不敢流通”等顾虑,努力实现数据可信流通。比如,福建省公共数据资源开发服务平台采用数据加密、脱敏脱密、数据沙箱、区块链等安全技术手段,通过“可用不可见”方式向社会提供数据服务。创新机制和技术,促进数据合规高效流通使用,数据要素市场发展就有了坚实基础。
丰富应用场景、推动高水平应用,是激活数据要素价值的根本途径。中国科学院文献情报中心支持上海药物所从文献中挖掘数据,为新药研发提供助力;浙江舟山港航和口岸管理局打通江海联运数据,完善管理流程,推动江海直达配送每航次物流周期缩短4天以上;上海钢联电子商务股份有限公司打造系列商品价格指数等产业数据产品,有效提升大宗商品流通效率……数据价值,只有置于应用场景中才能被充分挖掘。加快数据开发利用,必须推动数据要素多场景应用、多主体复用,创造多样化的价值增量。
党的二十届三中全会《决定》提出,“培育全国一体化技术和数据市场”“建设和运营国家数据基础设施,促进数据共享”“加快建立数据产权归属认定、市场交易、权益分配、利益保护制度”。随着政策供给不断优化,各类数据将实现有效整合与深度利用,数据资源支撑经济社会发展的战略性、基础性、先导性作用也将更为凸显。
文章归纳:
这篇文章是一篇关于数据开发利用的时评文章,它强调了数据在现代经济社会发展中的重要性,并提出了一些关于如何更好地利用数据的观点。以下是文章的概述和精妙之处:
概述:
- 数据的价值:文章指出数据的价值只有在应用场景中才能被充分挖掘,强调了数据开发利用的重要性。
- 数据作为生产要素:文章提到数据具有规模报酬递增和复用成本低的特点,并且随着技术的发展,数据生产规模快速增长。
- 数据优势潜力:文章指出我国拥有海量数据和丰富场景的优势,但目前这些优势尚未完全释放。
- 公共数据的开放利用:文章提到公共数据的开放利用对发展数据要素市场具有重要意义,并举例说明了一些地区在这方面的实践。
- 数据流通与安全:文章强调了数据流通的重要性,同时也指出了数据流通中存在的隐私泄露和滥用风险,并提出了一些解决方案。
- 应用场景的丰富性:文章通过一些具体案例展示了数据在不同领域的应用,强调了数据在实际应用中的价值。
- 政策供给与数据整合:文章提到了政策在数据开发利用中的作用,并展望了未来数据资源在经济社会发展中的战略性作用。
精妙之处:
- 数据与应用场景的结合:文章精妙地指出了数据的价值并非孤立存在,而是需要与具体的应用场景相结合才能发挥出来。
- 数据生产与技术发展的关联:文章通过数据生产总量的增长,展示了技术进步如何推动数据生产规模的扩大。
- 数据保存与使用的现状分析:文章通过数据保存率和使用率的统计数据,揭示了当前数据利用中存在的问题。
- 公共数据的开放与授权运营:文章提出了公共数据开放利用的新机制,为数据要素市场的发展提供了新的思路。
- 数据流通与安全的技术解决方案:文章不仅指出了数据流通中的风险,还提出了具体的技术解决方案,如数据加密和区块链技术。
- 政策供给与数据整合的前瞻性:文章对政策供给的讨论显示了对数据整合和利用的深刻理解,以及对未来发展的战略性思考。
- 案例的丰富性:文章通过多个领域的案例,展示了数据在不同场景下的应用,使得论点更加生动和有说服力。
总的来说,这篇文章通过深入分析数据的价值、生产、利用以及政策供给等方面,为读者提供了一个全面的视角来理解数据在现代社会中的重要性和潜力。
思维导图如下: